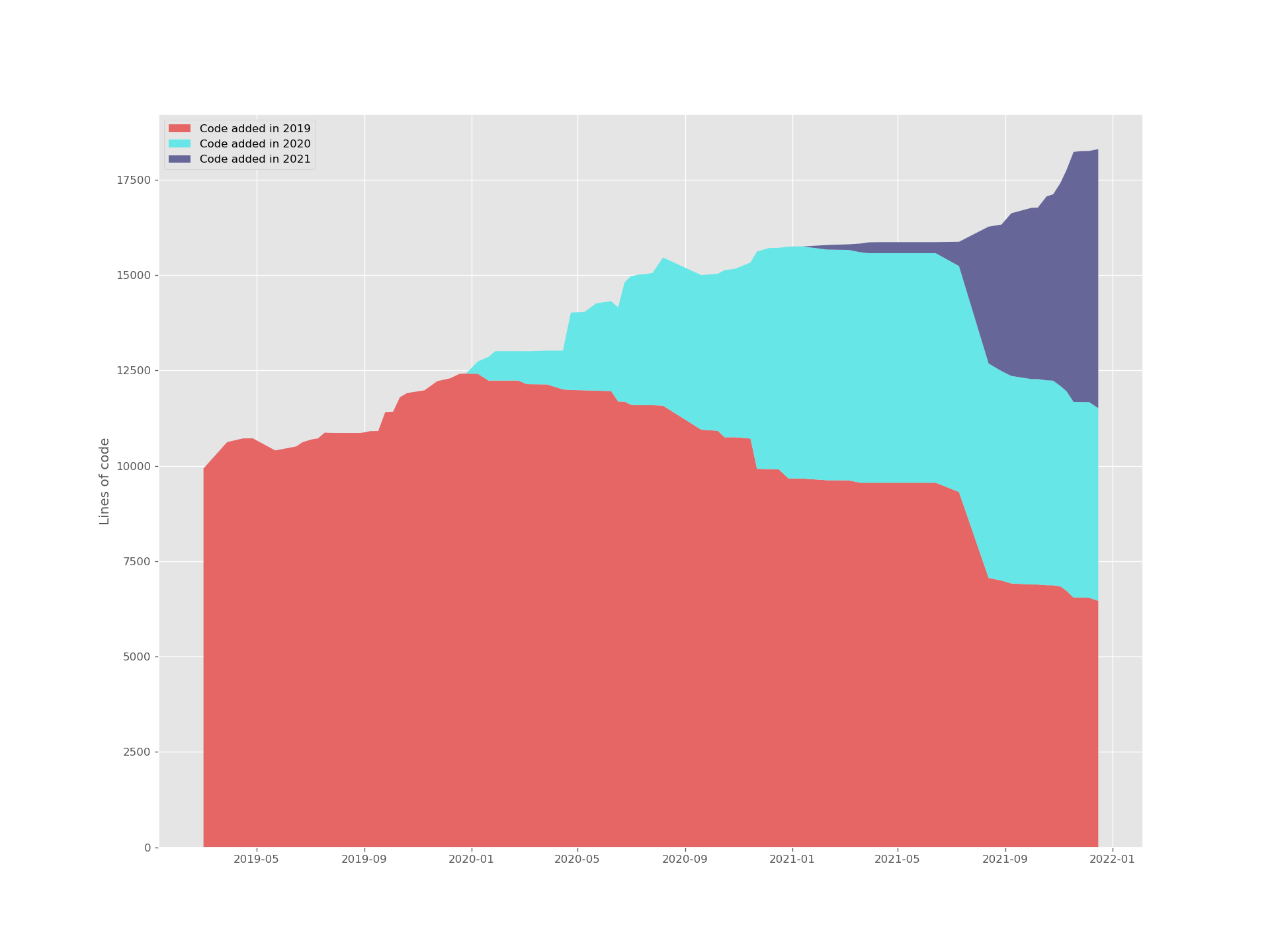
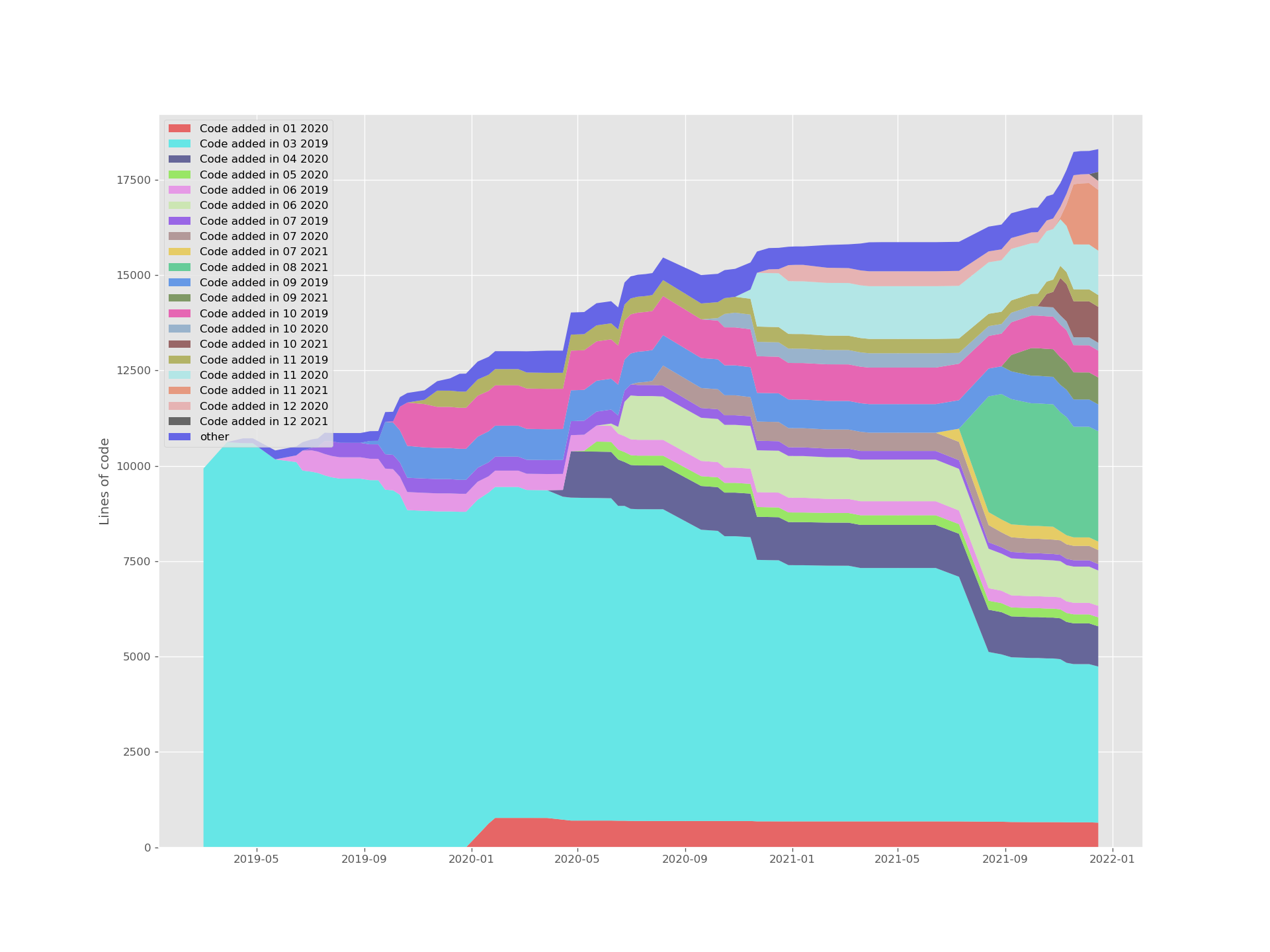
Ran it on phoc as well - it doesn’t tell the whole truth since the repository did not preserve rootston’s history, but at least some trend can be noted:
Eyeballing the two graphs, it looks like 25% (4.5/18) of phoc’s lines of code come from rootston and 9% (1/11) of squeekboard’s lines of code come from eekboard. I thought about running a diff on Megapixels vs Millipixels, but I think that people who care about this stuff already appreciate the work that the Purism devs do, and the rest won’t change their mind one way or another.
More worryingly is that that kind of metric encourages poor coding practices. Cut-and-paste reuse takes less time and gives higher “productivity” … whereas taking a bit of time to factor the code properly will take more time and give lower “productivity” but may ultimately save cost in future maintenance.
A flexible implementation may take longer to design and implement and hence give lower “productivity” but should save cost in future development.
Against that, is the consideration of … writing dense, obscure, hard-to-maintain code may look like lower “productivity” but again the real cost is in future maintenance.
Organisations that have a mature software development process understand and manage all that e.g. through code review but that in turn results in lower effective “productivity”.
I agree that more code is not necessarily better code and maintenance of old code is often much harder than writing new code (and certainly less fun!). Another issue is that comments usually aren’t included by counters of lines of code, but well documented code is much easier to maintain. Another question is whether the lines of code from different languages should be counted in the same way. I know that it takes me less time to write a line of Python or PHP than C, C++ or Rust, but usually I can do a lot more work with a line of Python or PHP.
LOC is easy to define and count and it is widely used. As I see it, lines of code is better than nothing, but I would be curious what proposals there are to replace LOC as the standard metric.
Maybe you can weigh editing 1 existing line (presumably to do maintenance work) the same as adding 2 new lines, but then you get into debates about whether someone is just tidying the code to make it easier to read, fixing a bug or refactoring the code to make it more maintainable or work with new changes. The relative benefit is different, so then you can get into arguments whether all edits should be counted the same.
It is difficult to collect other information, such as the amount of hours worked, and some programmers can do more in less time than others, so that also doesn’t seem like a good standard to me. At any rate, that is my initial thought without knowing much about the topic.
Vast majority will be from Megapixels, and the result won’t be particularly useful because of formatting noise (which, thinking about it now, is also true for phoc). Millipixels isn’t really going to stay around, so it’s probably not worth it to think about its code for too long
If it is a conscious choice nothing to say, but if it is only for sparing letters I might ask: have you thought about the possibility of using “GNU/Linux” instead of “Linux” when you refer to the ecosystem and not the kernel in your blog?
I always love your investigations about the Librem 5 and GNU/Linux phones by the way
I would like emphasis that line accepted by Linux kernel review process count two to 20 times more time than line in self maintained project. And that is good thing because it keeps that probably world wide most complex code with the highest number of contributors in the maintainable state. Much more problem is bad line of code in the project over which you stumble again and again and screw the new code to fit into the code than some missing feature…
I used to make a point of writing GNU/Linux, but I no longer think that it is something worth arguing about any more, now that GNOME is no longer is part of GNU and there is little active dev work being done on GNU Tools, although everyone still uses them.
I still make a point to write “free/open source software” or “FOSS”, because I’m closer to the “free software” line of thinking than the “open source” camp, but I actually have quite a few criticisms of the way that the FSF operates, and I don’t think that arguing about the use of certain words is the best way to promote the message of free software. I understand the arguments, but I don’t find that they convince many people, so I try to focus on the tangible benefits when talking about free software.
My mind went in the opposite direction, and I started to pay much more attention in writing GNU/Linux only after the hate letter signed (written?) by the GNOME Foundation. Before I did not bother much.
You have defended Purism when fire was coming from every direction, I am sure you can understand my point of view.
Function Point Analysis is what is probably the best standard available for software metrics today. Capers Jones is the best author to read on explanations why FPA is a good standard. He has a lot of data to back his assertions.
The statistics sorted out: A line of code = a line of code in whatever language you code .. Don’t convert LOCs in one language to LOCs in another. (e.i. when coded in C++ don’t count compiled LOCs, stay in the source code).
The point is that, in whatever language you code, the result is that a line of correct code takes about 1 hour (due to Barry Boehm a.o., the ‘b’ power in the efficiency formula has the tendency to become higher in bigger projects). This is a human thing: humans are not able to produce correct code in one go (only God’s have that privilege). So, during the coding process a lot of testing, correction, refactoring, etc. is needed before a code is ‘ready’.
If a programming language is better suited for a certain task the overall efficiency increases, not the LOCs.
FPA is not well suited for embedded coding. (FPA calculation has changed over time, in the early days too much weight was given to UI elements, until design tools where invented. FPA is for general coding projects still the best method for estimating workload (proposal costs). Be aware of gross inaccuracies when applying for projects with lots of HW interfacing.
IFPUG is now recommending SNAP metrics for hardware interfaces. This is separate from FPA, but using both will give you better accuracy.
It should be noted that embedded projects are much larger than in the past, so FPA is valid for many embedded systems. For example, the Librem 5 is considered an embedded project, but a lot of the works exists outside of the kernel and drivers.
“Ask” Boehm since he was the one who said that the parameters of the above-quoted equation depend on whether the software project is “organic”, “semi-detached” or “embedded”. I guess he must have had some way of classifying a software project i.e. criteria for deciding which category is applicable. A visit to your local (e.g. university) library may turn up copies of relevant early research papers or of his book(s).
According to COCOMO (Boehm), which is written in 1981 (! = no IoT yet ) embedded is defined as:
Embedded – A software project with requiring the highest level of complexity, creativity, and experience requirement fall under this category. Such software requires a larger team size than the other two models and also the developers need to be sufficiently experienced and creative to develop such complex models.
Today you may call e.g. the (software) integration of a camera and a processor (never done before) as such. Even if the team is small in size (1-- 3 programmers). In general, all these unknown integrations are extremely difficult to estimate. Whatever metrics I tried, the reality was always worse ..