Oh, could be taken either way. But it is a mighty sentence, that’s for sure.
2 Likes
Store to tape and lock it up.
Changes require signature sign-off on a piece of paper by two officials †.
Also lock up the sign-off list.
(“Tape” is a metaphor, store to any offline medium.)
Compare the online file(s) with the offline file(s) frequently.
† We used to call this “two-person integrity”. We’d use it just to open the door of a SCIF. That kind of security has gone by the wayside it seems.
2 Likes
… which was kind of my point.
You can go to great lengths to create a robots.txt file with a hundred lines (literally, here, q.v.), steering robots away from a long list of unsuitable URLs but bad robots are just going to ignore it anyway - or even use it to reach disconnected parts of the URL graph. So why not “all robots, disallow all URLs”? In other words, my question was actually about good robots, not bad robots.
Or to put that (rhetorical) question a different way … what benefit does Purism accrue from good robots? and does the benefit outweigh the cost (from good and bad robots)?
1 Like
Coming back more directly to topic … did anyone test from a mobile phone? (might need lapdock - no idea how well that web site works on a phone-sized screen)
At least here, mobile phones are most likely to be behind CGNAT and I am not sure how sticky the public IP address is, which then influences the behaviour of any state (e.g. cookies) that is confined to a specific IP address. However the documentation was not crystal clear on whether a successful result can be shared between IP addresses.
1 Like
I think cookie is per browser, not per IP address. So changing your IP address should not invalidate the cookie. Firefox on byzantium and crimson/bookworm seems to work fine. Gitlab is very responsive to mobile screens.
1 Like
I think if the robots don’t take the whole server down and if other users are not affected, it would be fine.
1 Like
I think so too - but that leaves open the obvious attack vector that one member of a botnet does the proof of work but then shares the cookie with all the other members that will actually be traversing your site at high speed thereby DDoSing it.
(I have the same issue on some of my web sites with the anti-spam mechanism, which uses crypto to incorporate a bunch of information in a cookie, including the IP address to which the cookie will be sent. Should it then validate that the cookie is handed back by the same IP address? It’s a trade-off. By including the IP address it leaves open the possibility that a future sysadmin option would allow the IP address to be validated as the same.)
1 Like
I’d let the anubis author figure out the best defenses for now, that works against most of the bots, even if not stopping 100% of the bots.
1 Like
I got a 503 error (Service Unavailable)
1 Like
Because I made a mistake in the configuration. Ip address should be in CIDR format. It should work now.
2 Likes
It does. Animegirl was happy.
1 Like
Link titles are coming correctly after an exception was added for forums.puri.sm in bot policy.
1 Like
Works fine.
Anubis is now deployed on https://source.puri.sm ![]()
Test for link preview: Help · GitLab
CPU usage over last 12 hours, big drop from ~80% to ~6%, if this trend continues, we may be able to reduce the CPU power and save money.
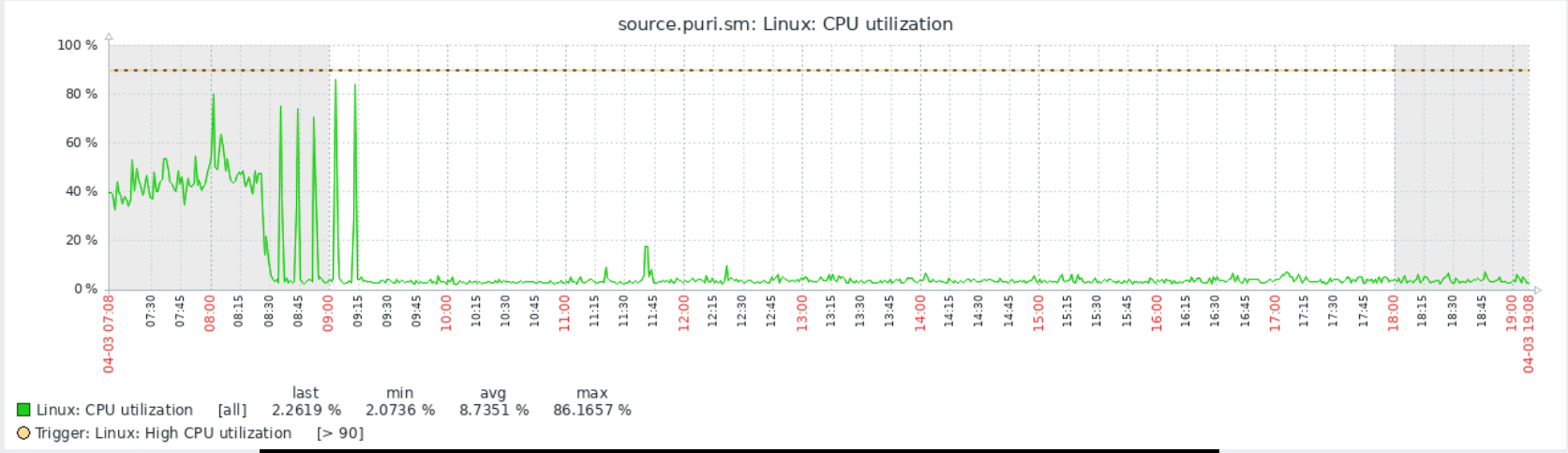
4 Likes
At a quick test, working normally for me (just the one upfront visit from the weigher of souls).
2 Likes
I found a resource that may be useful for protecting Purism’s infrastructure against additional AI training:
2 Likes
Since Service Desk was no longer creating tickets with anubis, we have removed anubis for now. Once we figure out how to make anubis and Service Desk work together, we can re-enable it.
2 Likes
Yeah, so what’s the deal with that Anubis thread?
1 Like
It’s purely an operational matter.
Automated software may traverse your web site. Historically, that would have been search engines indexing your site. These days it is more likely to be someone training an AI model using the content of your site. Either way, this is a problem if the automated software imposes a high load on either the site’s connection to the internet or the site’s CPU allocation or both. So web sites look at ways of discouraging or taming that automated software.
Anubis is one such approach. It aims to impose a high CPU load on the automated software, thereby discouraging it and/or slowing it down.
“Tar pits” are another approach.
Or the traditional approach of creating a resource /robots.txt on your site in order to direct automated software - but this can of course be ignored.
Or some of the other approaches mentioned in an earlier reply in this topic.
Feel free to ask a more detailed question.
A lot of this is explained in the link in the OP and in the links therefrom.
1 Like