I just tripped over a DuckDuck item that disclosed Facebook means and ways of stalking users, even if the user is not registered at Facebook.
This is DuckDucks clip:
Security Researcher Finds Facebook App Tracking iPhone Movements [forbes.com]
Even if you’ve asked Facebook not to track you in your iPhone privacy settings, “Facebook is using the accelerometer on your iPhone to track a constant stream of your movements,” says Zak Doffman. Delete Facebook to stop their sneaky data harvesting.
QUESTION:
Is there a “accelerometer” in the L-5, or in the PURE O/S code or similar FB spyware?
“9-axis” by ST, LSM9DS1 (gyro, accel, magnetometer)
The L5 does not come with a Facebook app. I don’t know if there is a Facebook app for Linux. I doubt there is an official one that exploits user’s privacy.
There are approaches to install android apps on Linux. I don’t know how far the development is but it might become possible to install the official Facebook app.
Despite the initial installation the user is responsible for what the user installs. I personally trust free software
How can the system be protected from being exploited by an arbitrary app similar to what the Facebook app does? I don’t know.
Why would anyone break out of a prison cell, only to return asking their jailers to let them back in. Facebook is closed source, closed everything. Just don’t install Facebook and you have nothing to worry about. If you don’t agree to their terms of service, don’t install their software or access their servers and they spy on you anyway, then they have violated the law.
It’s not about beating the devil at his own game (using Facebook while successfully maintaining your privacy - even if that were theoretically possible). It’s about not doing business with the devil at all.
Accelerometer is used to detect device movement and orientation. On Librem 5, currently applications can only receive device orientation (normal, bottom-up, left-up or right-up) via iio-sensor-proxy, anything more specific requires superuser privileges (this will likely change in the future to allow such uses as motion-based games, but we would like to make it clear that an application is using sensor data so it can’t do it sneakily without user knowing).
As @StevenR says, I don’t think you can simultaneously use Facebook and complain about the fact that Facebook violates your privacy but …
if you must use Facebook then for the love of gohod don’t install the app. Just use the web site. That at least reduces the attack surface.
If you must use the Facebook app () then there may eventually be container-like technology that allows you to run the app but limit some of the leakage e.g. provide false location information and/or prevent access to location information and e.g. the same but for sensor information and e.g. restrict internet hosts that it can connect to.
It also may be the case that one day somebody reverse engineers enough of the Facebook app so that you can run a safer, open source, unofficial client app (where safer means that the most obnoxious stalking has simply been omitted from the code).
Hey, I just want to point out my favorite feature of Gnome Web, which is the ability to make sandboxed Web apps from arbitrary web pages. This completely isolates the web service in question, and gives you control over what it can/can’t access, as far as I can tell. I have used it to make a Facebook App on my L14.
Can anyone comment on the relative security/isolation of these web apps, and/or how to make them more secure if they aren’t inherently secure?
Thanks all for the info. I get it now, and am too narcissistic I guess to think that everyone else is using a leash (sans I and the great people here), and my only use so far with Pure O/S in on a desktop workstation.
SUMMARY:
From the answers, I gather that it won’t break Pure O/S because therte is nothing to break and by all accounts, it seems FB is targeting Apple phones - so far.
I do not use FB. But because some goods and services companies seem to think it’s the only way to have a web presence, I need to use a windoze laptop just for such purposes to access client FB pages - then take a shower.
On the Windows box, I visit some sites and know that they tried report to FB, my location, time, check cookies, CPU, APU, GPU Font fingerprinting, and more. All the site needs is AddThis and even without a DFB app, or account, FB still stalks.
The difference I see between non-FB accounts and this new poison is with Apple the “app” reports a stream of movement, whereas with other O/S’s (my desktops) they can only use the draw-the-lines from point A to B to C etcetera.
I see hospitals using something similar where a hospital staff location can be detected and *A.I., knowing that persons’ job, and who else is available in any given arena can assign the right person to the next task.
I would rank the options from most private to least private as:
containerisation within the web browser
vanilla web browser
containerisation of app
vanilla app
There isn’t any absolute accuracy to the above because it depends on
what APIs are exposed to the code,
what other more subtle forms of leakage occur within the environment, and
what controls are offered to the user to control what occurs
in each of the respective 4 options.
In other words, for example, as new APIs are added, some given choice may reduce in privacy.
An open source environment may not be the most promising target for this discussion since it is assumed that
a) any leakage by evil code will be visible
b) any evil code can be surgically removed.
Hence another approach to this whole problem would be to ask Facebook to release an open source version of their app. Best of luck with that.
Most of the leakage with Facebook occurs on the server side anyway. If you voluntarily tell Facebook what you had for breakfast then, well, Facebook is going to know what you had for breakfast regardless of any technology on the client side.
Agreed, but it seems that so far, only governments are cracking down on something they are most likely jealous of. Governments aside, there doesn’t seem to be any organized NGO’s heck-bent on putting the giants in their place. Until there is a very loud noise, I don’t see FB taking their finger out of the air and being honest, transparent, and non-stalking.
Be careful what you wish for though. You can choose between a small number of mega-stalkers or a large number of mini-stalkers. Every web site can be instrumented for stalking by any number of companies. So there are just more copies of your data.
What I would actually like to choose is less stalking and more realistic options to avoid stalking.
Different countries take different legislative approaches. Competition law (in general terms, across many countries) favours what has (apparently) happened in the UK (breaking up monopolies, increasing competition) but in my country lack of competition favours government control. That is, the government finds it more difficult to control 1000 mini-stalkers than it does 3 mega-stalkers, both from a political perspective and from a practical perspective.
Facebook is the megalodon of data aggregators from which even non-members can hardly hide. (And which every business on the web willingly integrates into their operations without regard to our privacy.)
Hi @irvinewade,
I’d like to add that most web sites, not just the those that are a giants site, are built using any number of free and pricey templates available for any content management system, shopping carts, BBS’s, and so on, including that blogger WordPress. I have wiped up behind template installers (aka web masters) that unknowingly, or carelessly install those kiddie-kewl apps that animate, change colours, zoom, display dates, create forms, make menus dance and so on, with those blings having built in stalkers.
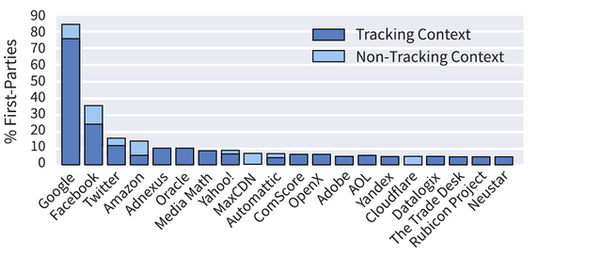
“Google trackers are actually lurking behind the scenes on 75% of the top million websites. To give you a sense of how large that is, Facebook is the next closest with 25%. It’s a good bet that any random site you land on the Internet will have a Google tracker hiding on it.”
I empathize for the Faceboogers that give up their privacy so they may post videos of kittens attacking a ball of yarn.
The more noise people make about it, the harder the peeps work to circumvent laws, and blockers. But many sites have to ask themselves, just what they are doing to visitor’s rights to privacy and clean up their act BEFORE government and public rage forces them to;
I found this image at DuckDuck that shakes the finger-of-shame at some peeps.
Of course DD is being polite calling it “tracking”. When something is “tracked” the route is recorded. But FB takes it way beyond that and is more deserving of the term ‘stalking’, as are most sites now days.
~s
p.s. I couldn’t link to and display the image - I’m sure they won’t mind.
Based on the numbers that @Sharon quotes, you should forget about Facebook for now and focus on Google - and that is my impression too. Google is a far greater threat to privacy. If Facebook is a megalodon (yes, I had to follow your link to know what that is) then what is Google? A megasun blackhole sucking in data that can then never escape from Google’s Big Data hoard?
I see what you did there with the aquatic metaphors. Sorry that I couldn’t continue it.
Yes, it is often convenience and expeditiousness rather than malice.
I don’t know whether that was web sites only but another mechanism by which Google tracks is by offering its public DNS servers, which conveniently work when your ISPs DNS servers do not. More recently Cloudflare has got into that game too, both with vanilla DNS servers and with DNS over HTTPS.
So Google and Cloudflare can associate your IP address with the domain names that you are looking up, and hence by reasonable inference with the web sites that you visit, even if the web site is not instrumented with Google spyware.
 ) then there may eventually be container-like technology that allows you to run the app but limit some of the leakage e.g. provide false location information and/or prevent access to location information and e.g. the same but for sensor information and e.g. restrict internet hosts that it can connect to.
) then there may eventually be container-like technology that allows you to run the app but limit some of the leakage e.g. provide false location information and/or prevent access to location information and e.g. the same but for sensor information and e.g. restrict internet hosts that it can connect to. book wanted it so badly.
book wanted it so badly.