When working with iptables it’s beneficial to know at least how to check that the rule(s) you are applying are being accepted and applied correctly and, after sending some traffic through the system you’d expect to hit the rule(s), check that the rules are actually being hit.
The first point is particularly important at the moment as many distros are moving to nftables on the back-end and the iptables executable is not talking with iptables directly on the back-end but rather it’s operating as a cli front-end to nftables, translating the given iptables rule(s) into nftable rule(s) sets. I have seen quite a few occasions where the translation is being borked on and silently swallowed for all but the most basic of iptables rules, i.e. the rules are not being applied and no error or warnings are being shown.
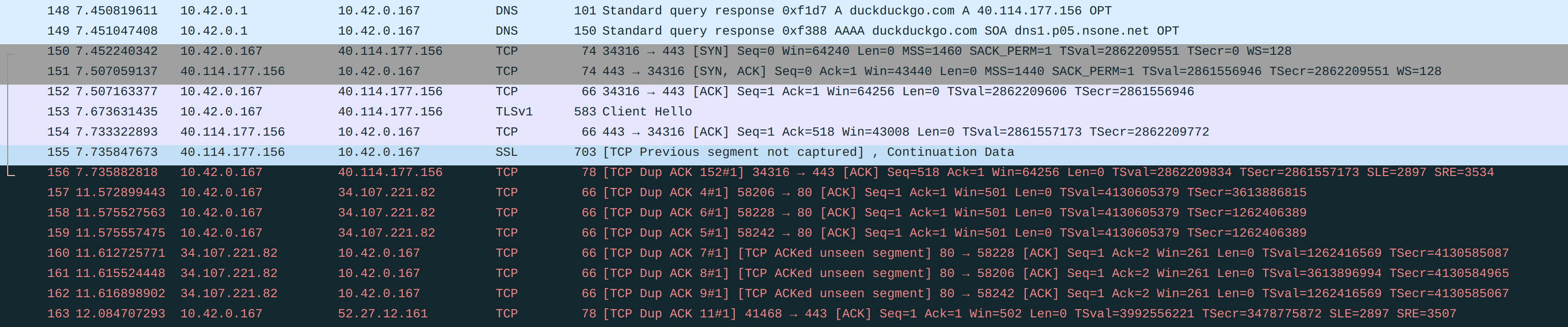
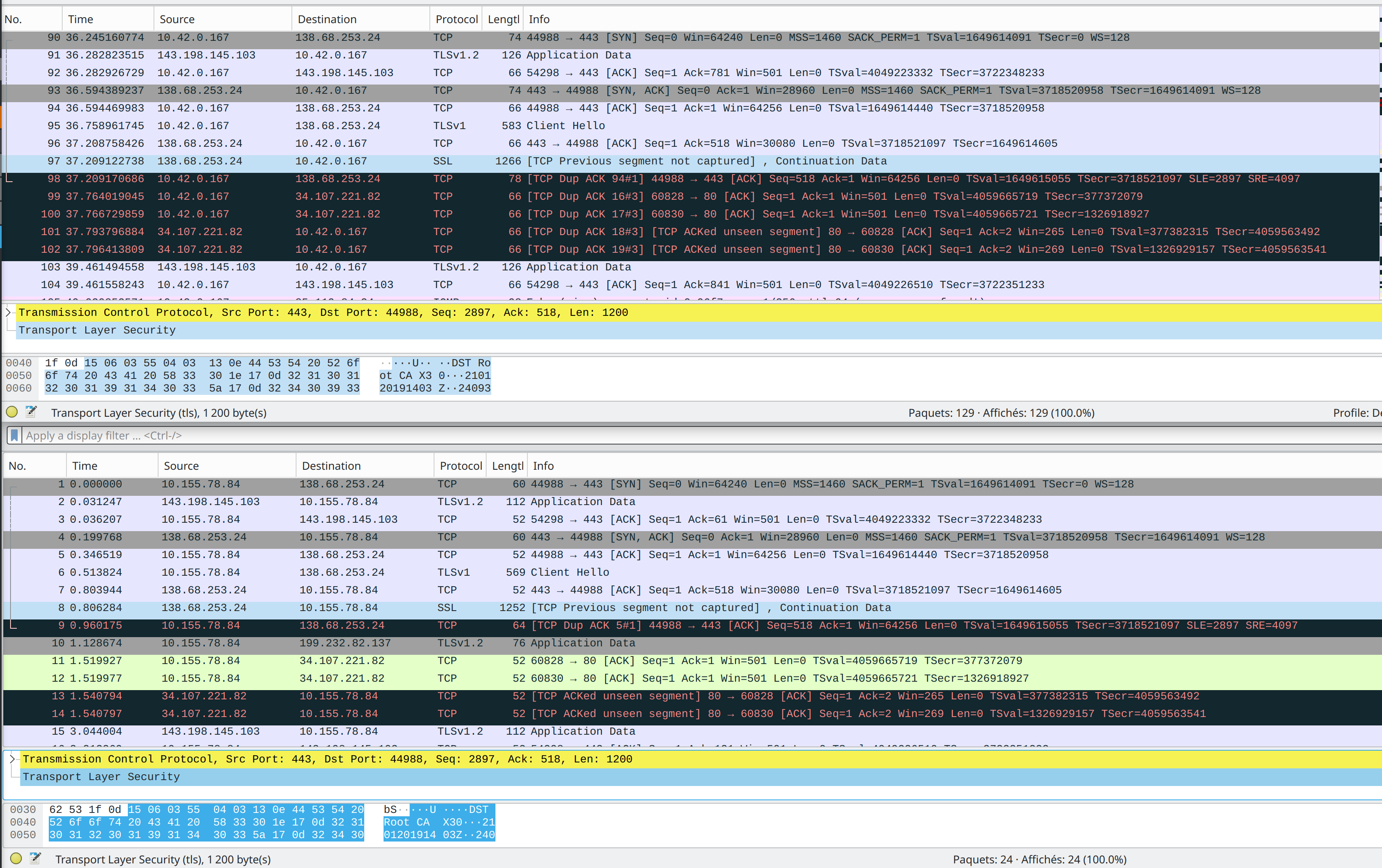
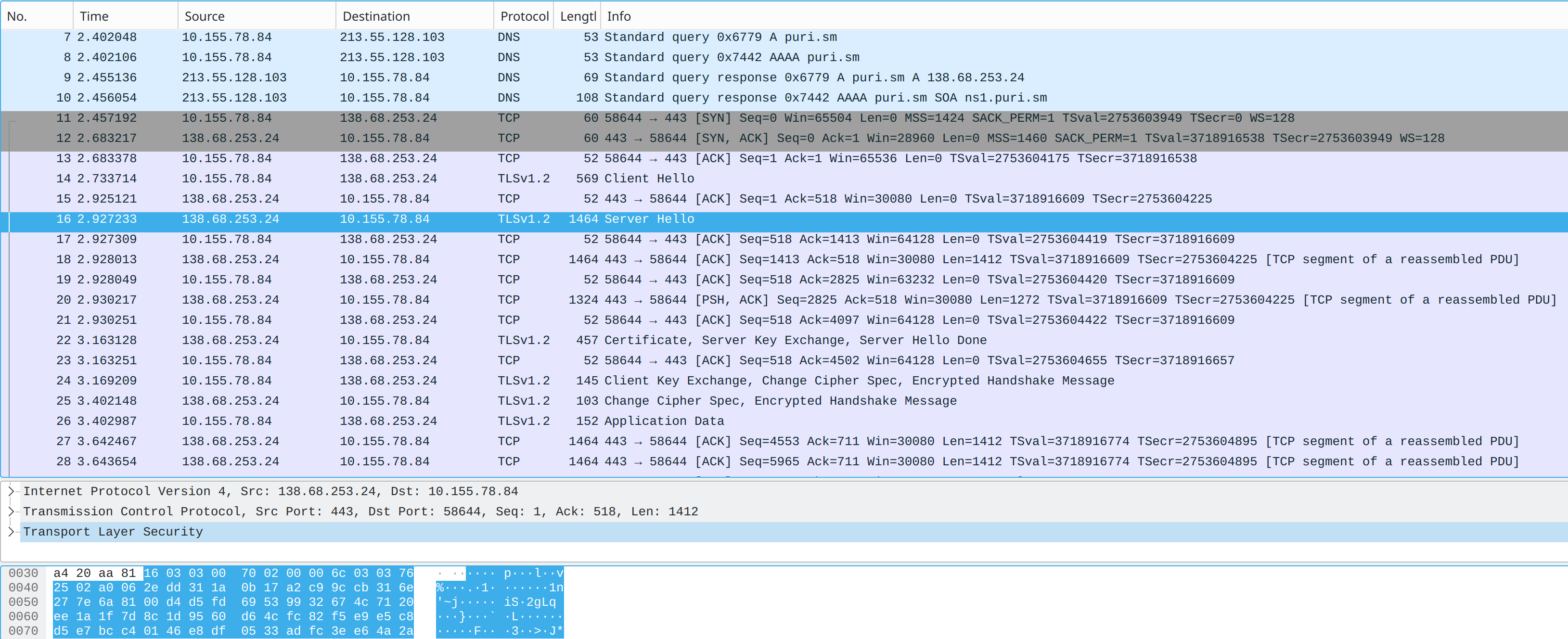
The cURL output suggest that you are not getting a TLS response from the server. The Wireshark capture screenshot you supplied in the issue you created shows packets are getting re-transmitted, given the info/details you’ve given in this thread I would guess that the re-transmission is a result of packet fragmentation. I’m not aware of the finer details of TLS in this context so can’t comment with absolutes, but, I do see this or very similar symptoms quite often which leads me to think that some implementations just can’t deal with fragmented packets.
I think it would be better to determine what sort of ( P )MTU figure you actually have to work with rather than throwing arbitrary numbers around. You could try some basic testing, take a problematic site/server, one that will respond to ping, and ping it with the “don’t fragment” (DF) bit set, varying the size of the packet narrowing down on what size passes or fails. For example…
loki@sputnik:~$ ping puri.sm -c 4 -s 1465 -M do
PING puri.sm (138.68.253.24) 1465(1493) bytes of data.
From router.internal.com (192.168.3.12) icmp_seq=1 Frag needed and DF set (mtu = 1492)
ping: local error: Message too long, mtu=1492
ping: local error: Message too long, mtu=1492
ping: local error: Message too long, mtu=1492
--- puri.sm ping statistics ---
4 packets transmitted, 0 received, +4 errors, 100% packet loss, time 59ms
loki@sputnik:~$ ping puri.sm -c 4 -s 1464 -M do
PING puri.sm (138.68.253.24) 1464(1492) bytes of data.
1472 bytes from static1.puri.sm (138.68.253.24): icmp_seq=1 ttl=50 time=153 ms
1472 bytes from static1.puri.sm (138.68.253.24): icmp_seq=2 ttl=50 time=153 ms
1472 bytes from static1.puri.sm (138.68.253.24): icmp_seq=3 ttl=50 time=153 ms
1472 bytes from static1.puri.sm (138.68.253.24): icmp_seq=4 ttl=50 time=153 ms
--- puri.sm ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 8ms
rtt min/avg/max/mdev = 152.551/152.764/153.084/0.340 ms
In my case, I started with a packet size of 1465 because I know I have an MTU of 1492 on the router interface here and a packet size of 1465 puts the payload at 1 over MTU which I expected to fail, decreasing the size by 1 to 1464 passes as it results in a payload of 1492 which is equal to the MTU.
Ping implementations vary quite a bit, you should check and confirm the correct argument switches for ping as implemented on your system. Outputs from ping also vary so you may not see exactly the same output at your end.
If the numbers you provided previously are still accurate (an MTU of 1464 on the Librem 5 WAN interface), I would expect pinging from your hot-spotted client with a packet size of 1436 would pass, while 1437 would fail, in which case the TCPMSS should be set or clamped to 1424. What ever the value is determined to be, it should be set on the router (in this case the Librem 5) rather than at client level as you’ll no doubt encounter situations where you’ll have clients on the hotspot that don’t have any mechanism to change/clamp/set their TCPMSS.