To combine information from several sources for a better picture of localization effort (translations and languages, regional variations as well) at the moment. Both, input and output, need to be (at least mostly) translated for an average user (most here understand English well enough, so we are not average).
Currently there are virtual touchscreen keyboard layouts for the following languages in Librem 5:
- de / German
- el / Greek
- es / Spanish
- it / Italian
- ja (kana) / Japanese
- se / Swedish [sv]
- us / English
- fi / Finnish
- no / Norwegian
- (fr / French pending)
- (ru / Russian in the works)
More conversations on them in Using non-latin language on Librem 5, How to translate Librem 5 software? and Librem 5 available languages.
And for comparison, a table:
- The core (mostly used) programs (currently conveniently translatable by community with translation tool Zanata) phosh and chatty (or chats, as it seems to be changing).
- In addition to those, I’ve also included translations tracking info (only clear UI - no “fuzzy” included which may increase percentage and usability) of a few most used programs: contacts management (gnome-contacts), web-browser (Gnome epiphany), email (Gnome evolution) and Pure maps (in Transifex).
- To condense the table, some languages that have variations etc. have been combined if they have essentially equal percentages.
- And for a better overall picture, after selecting those that seemed most translated, there are the general Gnome translation percentages by category as well (which include epiphany and evolution). Gnome has plenty more languages than are in this L5 list (and they have their own translation teams that can be joined too).
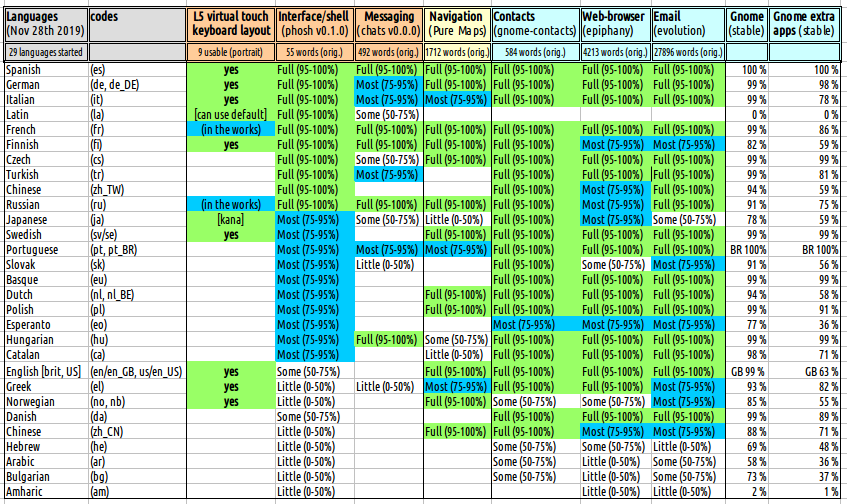
(edit: table updated 28th Nov 2019)
The points that are hopefully clarified from this:
- Better idea what keyboard layouts are most wanted/needed and where activity is needed (as you need input method as well as translated apps - assuming most early adopters know English is besides the point).
- Inversely: if there is a layout, it’s more motivating to translate and, thus, activity is needed to translate (identify “gaps” that can be easily fixed).
- Better idea as to how international / compatible the L5 is (currently) and who could comfortably buy/use it.
These are all in development and subject to swift changes (for instance, chats [formerly chatty] has just updated with a few strings and many languages now need to update translations). The listed languages cover almost 4 billion people but several large language groups are missing - as are many more of the smaller.
As I expect some coordination and up to date tracking/info is needed in this department now that phones are about to be distributed to masses globally. It would be nice if something similar could crop up somewhere official too - preferably automated (one can wish).
For those wanting to contribute to translations: https://developer.puri.sm/Librem5/Contact/Contributing/Translations.html, and as an opinion, it’s pretty easy for anyone - no programming skills needed. Good tips on making keyboard layouts in this thread!
For those wanting to track the issue with Zanata [has reliability issues occasionally but works now]: Zanata translation server is down and zanatas future? (Purism staff is considering long term solutions).
(edit to add: I’ll update the table at some point next month)

 . I actually proposed the same: to use certifikat and avoid potvrda or vjerodajnica when replacing certificate in order to reach more consistency and achieve clear continuity. Do you have some time to coordinate what is requested here (at least epiphany and evolution translation) properly? If you will I can do some of drafting and send it to you (or post here as draft … in more than several days) or vice versa do some revision of your drafting, but it will be tight with my time for doing this and therefore cannot be in lead/charge. Please contact author as necessary.
. I actually proposed the same: to use certifikat and avoid potvrda or vjerodajnica when replacing certificate in order to reach more consistency and achieve clear continuity. Do you have some time to coordinate what is requested here (at least epiphany and evolution translation) properly? If you will I can do some of drafting and send it to you (or post here as draft … in more than several days) or vice versa do some revision of your drafting, but it will be tight with my time for doing this and therefore cannot be in lead/charge. Please contact author as necessary. Although I was hoping other emotion to motivate
Although I was hoping other emotion to motivate 